总结了一些db操作的常见问题,让我们一起来看看吧
联合索引问题
- 在imo后台群唤醒活动中,用户数据表多达几千万,大数据这边,并未针对业务场景建立有效覆盖索引,导致后台SQL慢查询告警上千次,针对业务场景,提出以下优化,新增key1,key2索引覆盖,后台where条件严格按照stats_day,activelevel,categeory_id,cc顺序查询。
- 按照MySQL联合索引最左匹配原则,比如A-B-C联合索引,则针对A,A-B,A-B-C查询有效,而A-C,B-C,B,C则无效,where条件最好根据索引顺序进行
- 如果搜索条件过于复杂混乱,建议先与产品沟通清楚,确定好如何建立索引,严格把控搜索条件(从界面上)
- 以下为用户数据表(千万级别)
CREATE TABLE `xx_push_activelevel_categeory_day` (
`stats_day` date NOT NULL DEFAULT '2019-01-01',
`cc` varchar(10) NOT NULL DEFAULT '',
`activelevel` varchar(30) NOT NULL DEFAULT 'unknown',
`categeory_id` varchar(50) NOT NULL DEFAULT 'unknown',
`groupid` char(30) NOT NULL DEFAULT 'unknown',
`role` varchar(15) NOT NULL DEFAULT 'unknown',
`uid` varchar(25) NOT NULL DEFAULT '',
PRIMARY KEY (`role`,`activelevel`,`categeory_id`,`cc`,`uid`,`groupid`,`stats_day`),
KEY `role` (`role`,`activelevel`,`categeory_id`),
KEY `key1` (`stats_day`,`activelevel`,`categeory_id`,`cc`,`role`),
KEY `key2` (`stats_day`,`activelevel`,`categeory_id`,`cc`),
KEY `actl` (`activelevel`),
KEY `agid` (`categeory_id`),
KEY `cc` (`cc`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4
/*!50100 PARTITION BY RANGE (TO_DAYS(stats_day))
(PARTITION pd20200609 VALUES LESS THAN (737951) ENGINE = MyISAM,
PARTITION pd20200610 VALUES LESS THAN (737952) ENGINE = MyISAM,
PARTITION pd20200611 VALUES LESS THAN (737953) ENGINE = MyISAM) */;主键偏移问题
- 在单表大数据量的情况下,使用索引并不是唯一选择,当SQL分页查询,offset达到一定量(大概20w以上?)以后,就会出现慢查询现象,是由于MySQL根据索引查出一定量数据之后,会根据offset抛弃之前的数据
- 这意味着前20w数据的查询都是无用的,费力不讨好
- 可以采用主键id(INT, BIGINT类型)偏移,INT类型查询天生就有优势,又是主键索引,可以做到一部到位
- where条件最后,加上id排序,记录上一次的查询数据最后一条id,下一次查询作为偏移量,从而跳过前面无用的数据,再开始进行索引查询
- 以下是某个项目的例子(仅供参考)
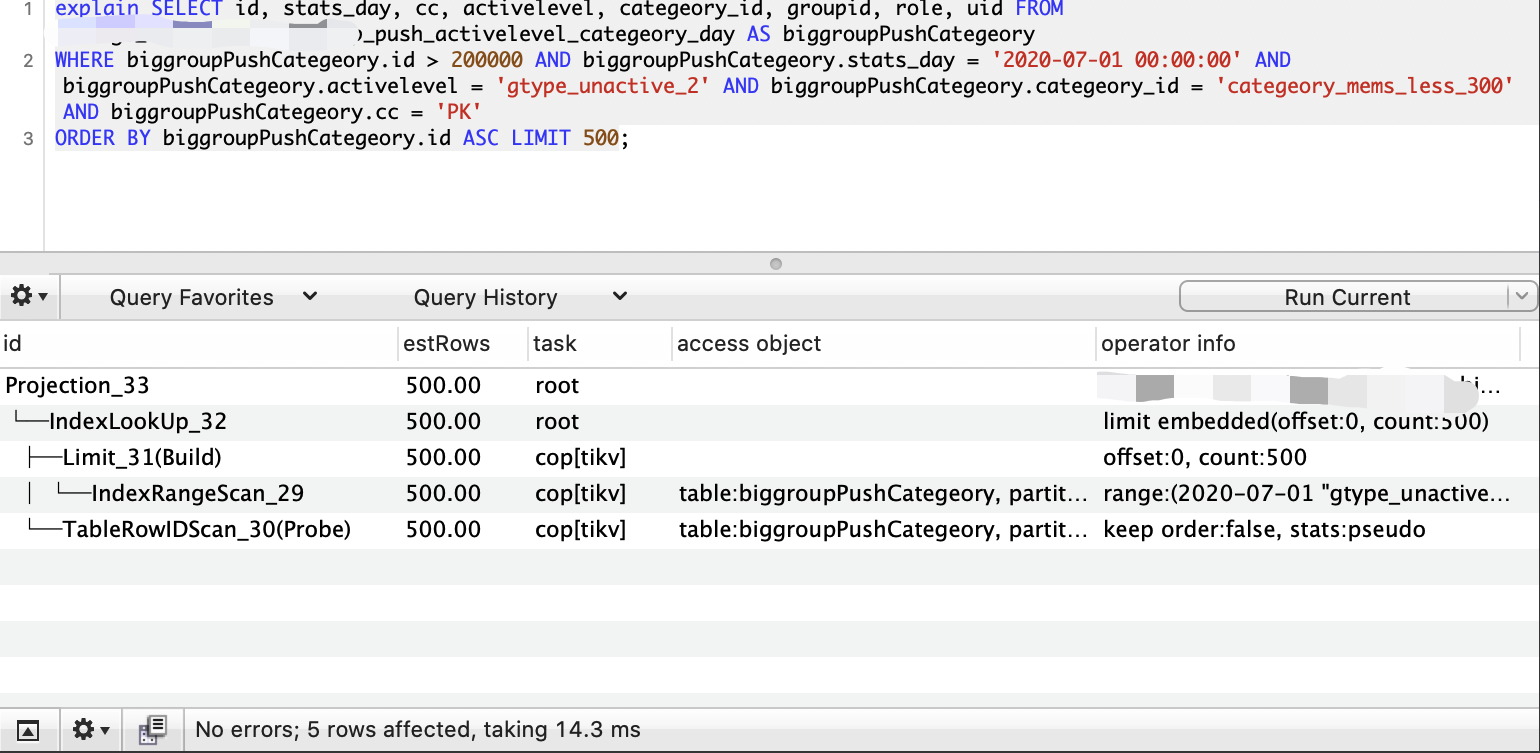
SELECT id, stats_day, cc, activelevel, categeory_id, groupid, role, uid FROM xx_push_activelevel_categeory_day AS biggroupPushCategeory
WHERE biggroupPushCategeory.id > 200000 AND biggroupPushCategeory.stats_day = '2020-07-01 00:00:00' AND biggroupPushCategeory.activelevel = 'gtype_unactive_2' AND biggroupPushCategeory.categeory_id = 'categeory_mems_less_300' AND biggroupPushCategeory.cc = 'PK'
ORDER BY biggroupPushCategeory.id ASC LIMIT 500;结果集过滤问题
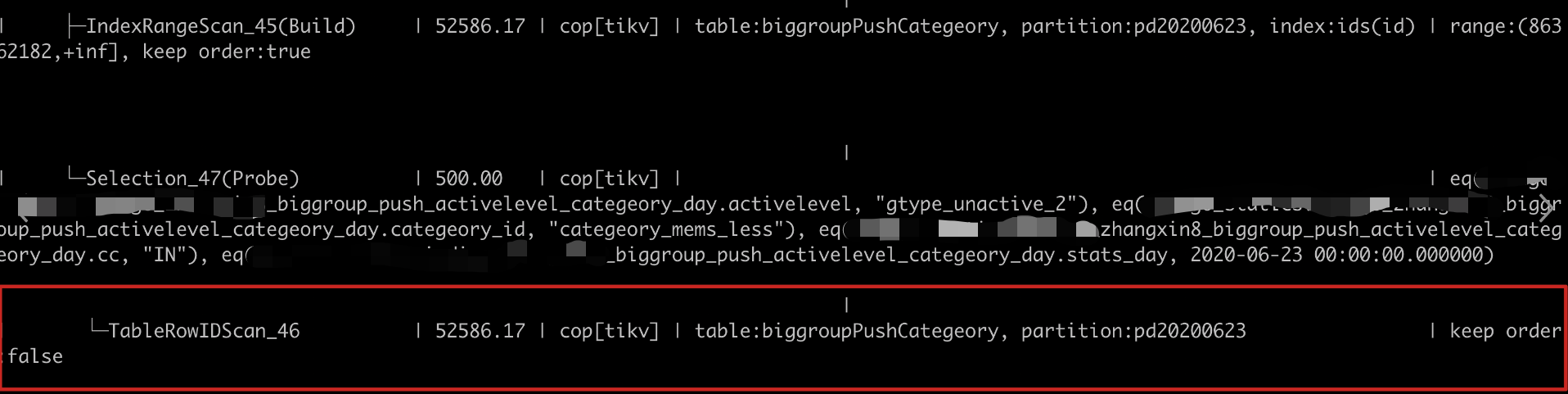
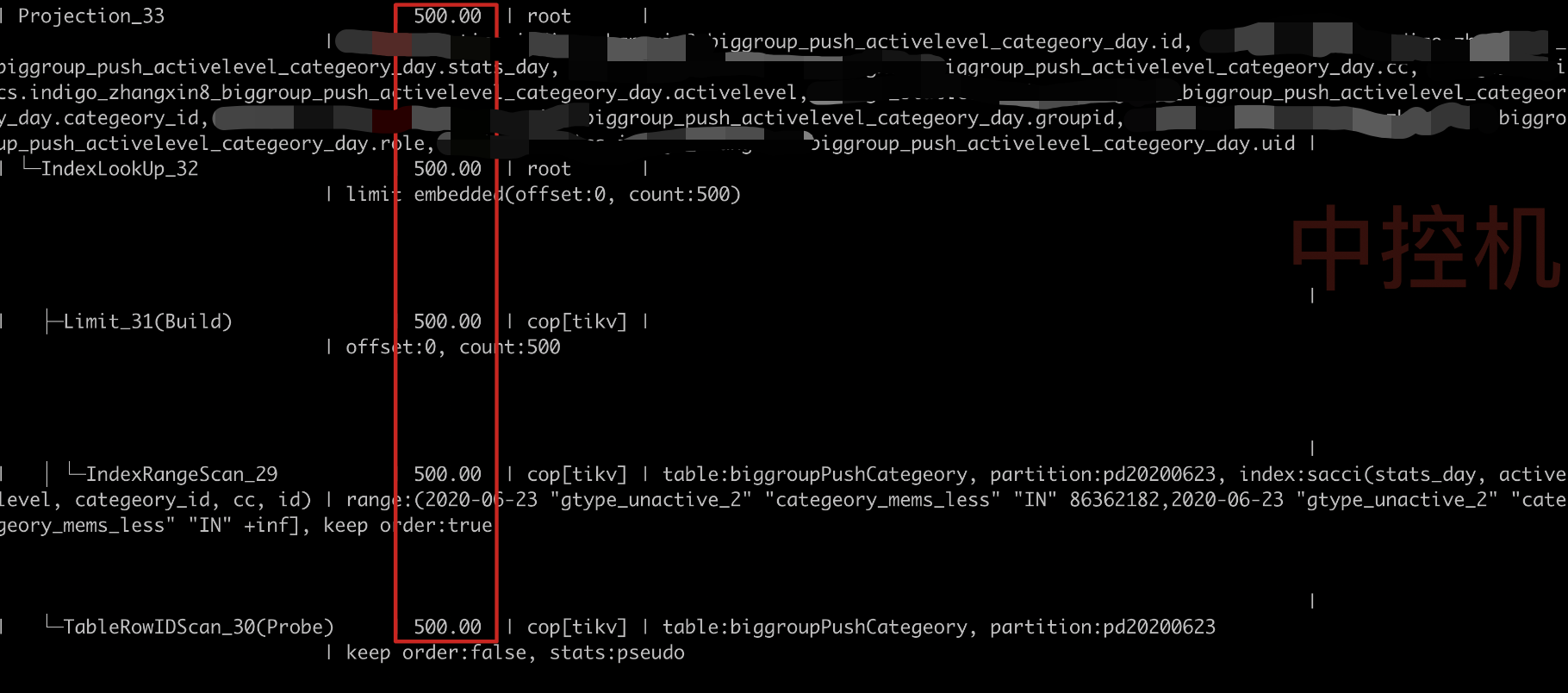
- 接上一个问题,当我们结合主键偏移+索引【KEY
sacc(stats_day,activelevel,categeory_id,cc)】搜索的时候,SQL这边优先根据索引过滤结果集,根据上面那条sql,我们可能会过滤出一个大结果集,而且结果集并不保证id有序 - 这时候我们需要重新修改索引键,加上主键id,例如KEY
sacci(stats_day,activelevel,categeory_id,cc,id),当我们进行索引查询取500行时,可以根据id>20000,直接命中500行并返回,不需要重新排序,也不会返回之前sacc索引的所有结果集 - 以下是优化前和优化后的对比图,性能提高了几十倍
优化前
优化后
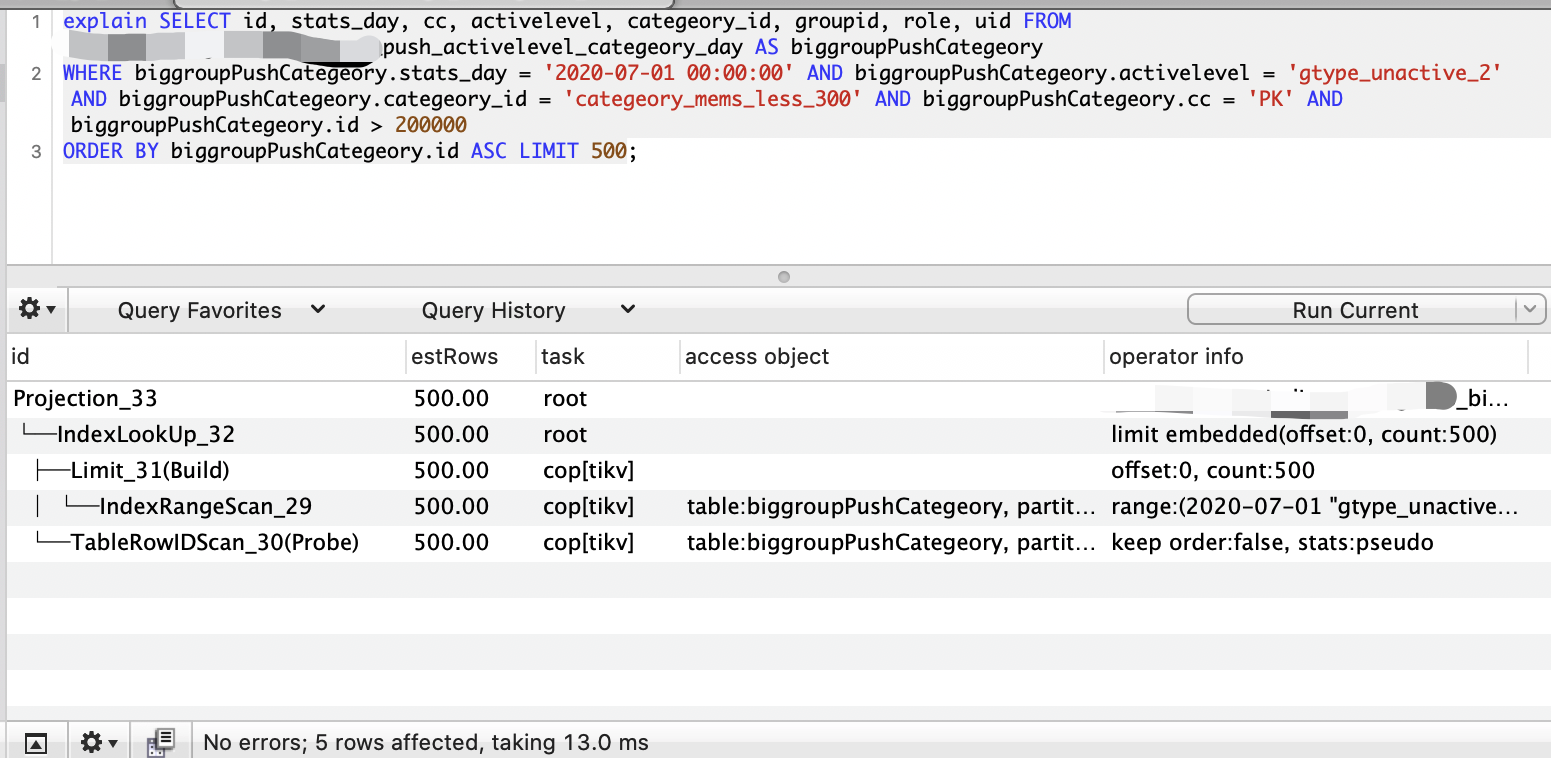
where条件顺序问题
- 接上一个问题,我们已经创建索引KEY
sacci(stats_day,activelevel,categeory_id,cc,id),如果我们把id放在最前,或者最后,会对查询的效率有影响吗?答案是没有。 - SQL执行是会被进行一系列预处理,让查询优化器选择最优的查询计划,所以where条件的先后关系不是优化器选择规则的一条,当然前提是你的where条件数量与索引一致,如果where条件少于索引数量,会根据最左原则优先查询。
- 总的来说,唯一会影响的就是where条件和索引的比对,以及跟order by等,跟先后顺序无关。
- 引申开来说,如果对ABC三个字段建立联合索引,一般来说,在创建索引时,根据区分度原则,尽量让A能够排除更多记录而不是B或C,在查询时,根据索引前缀匹配原则,尽可能让A条件精确,B其次,C看着办。
- 以下是id前后对比图