文章主要介绍了分布式架构里的微服务缓存原理与最佳实践,下面让我们来一起看看吧
为什么需要缓存?
程序存储在
disk中程序是运行在
RAM之中,也就是我们所说的main memory程序的计算逻辑在
CPU中执行
来看一个最简单的例子: a = a + 1
load x:x0 = x0 + 1load x0 -> RAM
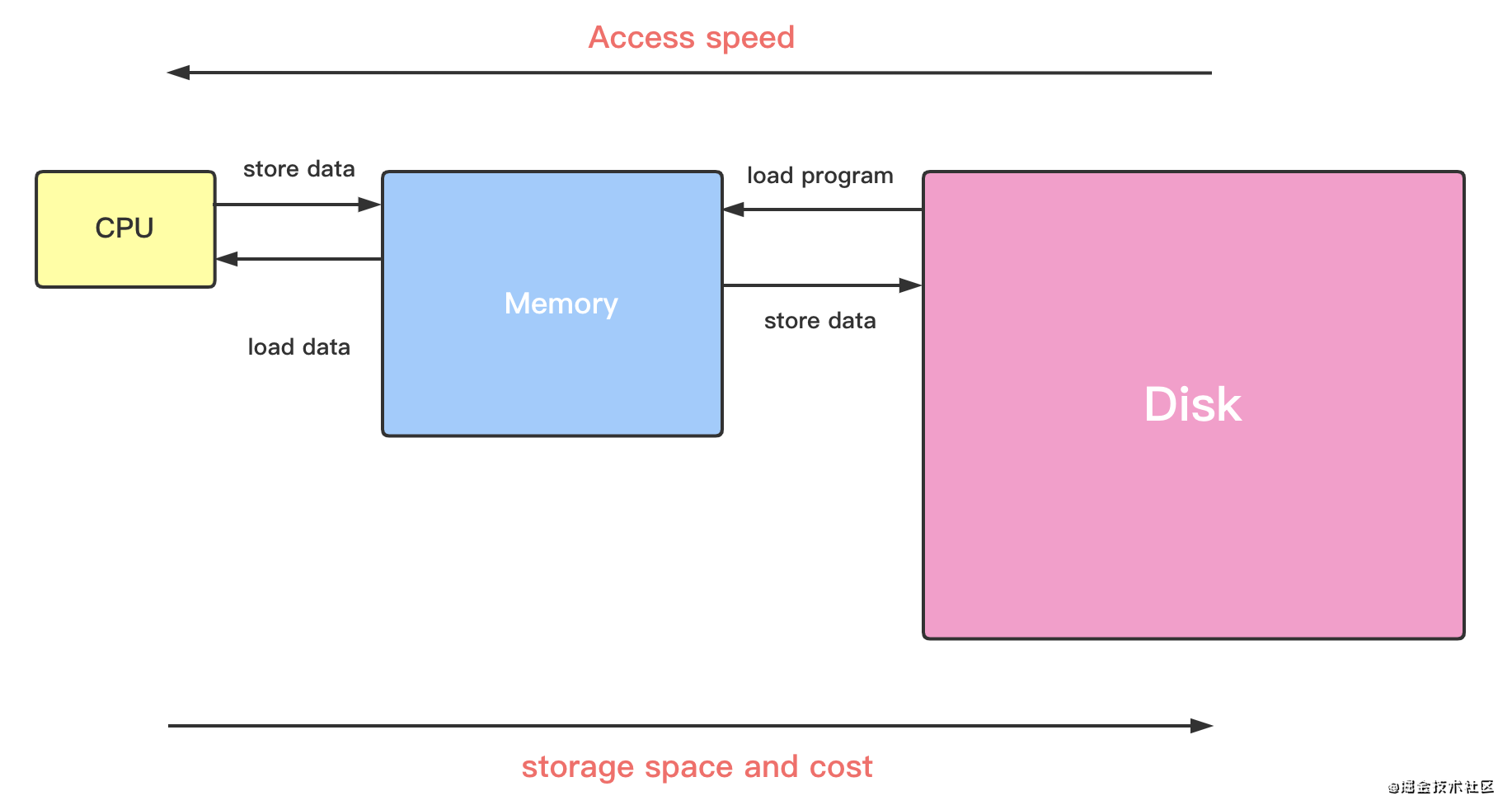
上面提到了3种存储介质。我们都知道,三类的读写速度和成本成反比,所以我们在克服速度问题上需要引入一个 中间层。这个中间层,需要高速存取的速度,但是成本可接受。于是乎, Cache 被引入
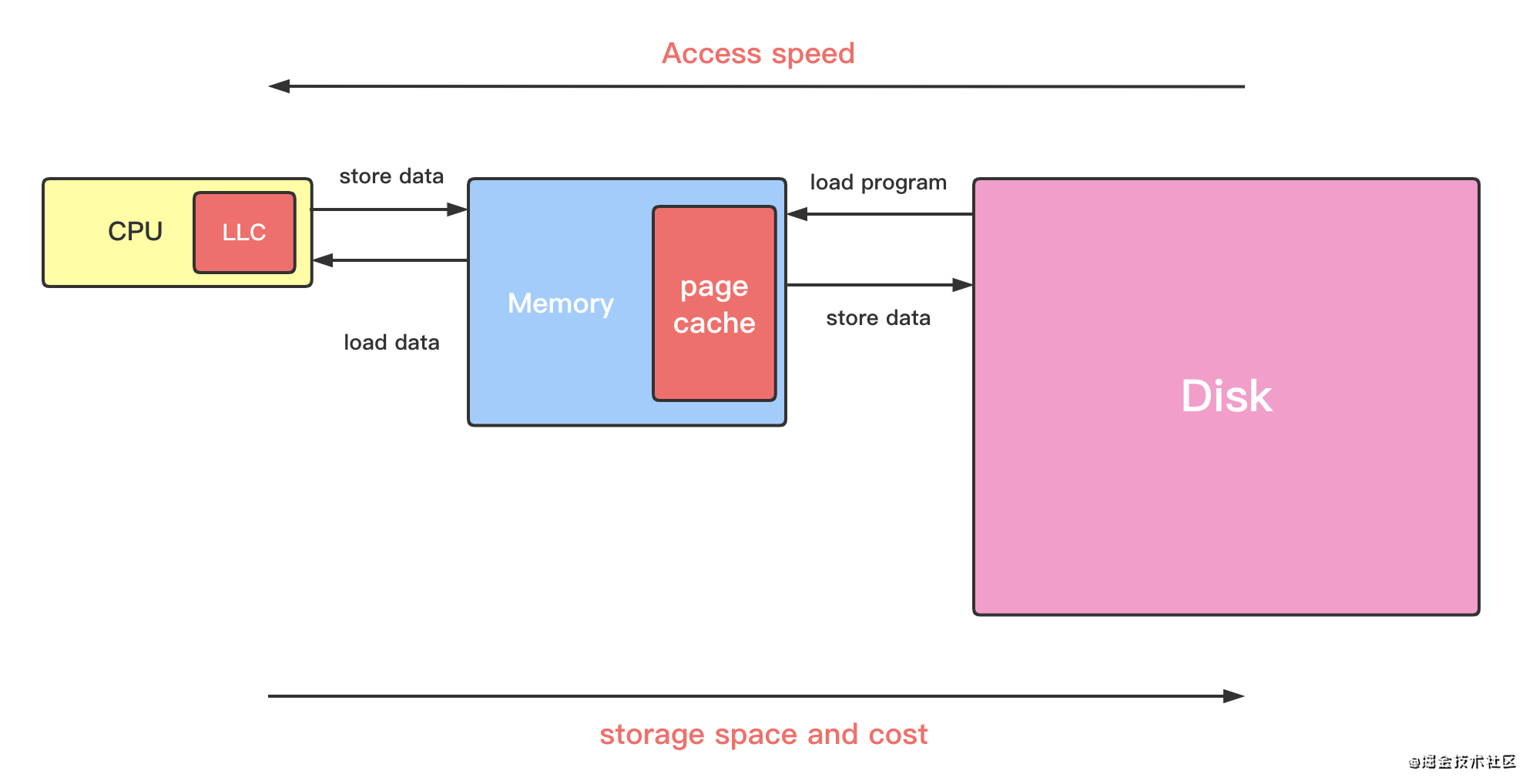
而在计算机系统中,有两种默认缓存:
CPU 里面的末级缓存,即 LLC 。缓存内存中的数据
内存中的高速页缓存,即 page cache 。缓存磁盘中的数据
缓存读写策略
引入 Cache 之后,我们继续来看看操作缓存会发生什么。因为存在存取速度的差异「而且差异很大」,从而在操作数据时,延迟或程序失败等都会导致缓存和实际存储层数据不一致。
我们就以标准的 Cache+DB 来看看经典读写策略和应用场景。
Cache Aside
先来考虑一种最简单的业务场景,比如用户表: userId : 用户id, phone : 用户电话token, avtoar : 用户头像url,缓存中我们用 phone 作为key存储用户头像。当用户修改头像url该如何做?
更新DB数据,再更新 Cache 数据
更新 DB 数据,再删除 Cache 数据
首先 变更数据库 和 变更缓存 是两个独立的操作,而我们并没有对操作做任何的并发控制。那么当两个线程并发更新它们的时候,就会因为写入顺序的不同造成数据不一致。
所以更好的方案是 2 :
更新数据时不更新缓存,而是直接删除缓存
后续的请求发现缓存缺失,回去查询 DB ,并将结果 load cache
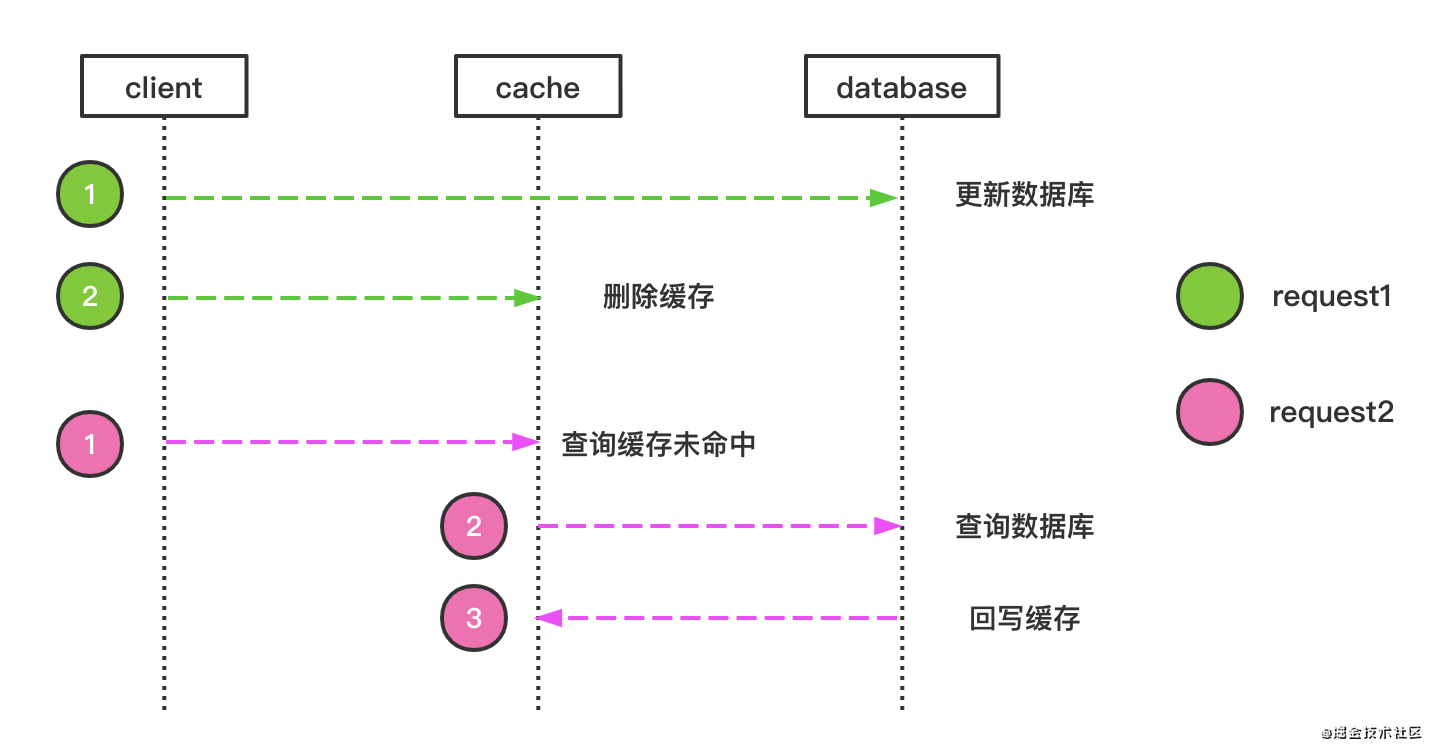
这个策略就是我们使用缓存最常见的策略: Cache Aside 。这个策略数据以数据库中的数据为准,缓存中的数据是按需加载的,分为读策略和写策略。
但是可见的问题也就出现了:频繁的读写操作会导致 Cache 反复地替换,缓存命中率降低。当然如果在业务中对命中率有监控报警时,可以考虑以下方案:
更新数据时同时更新缓存,但是在更新缓存前加一个 分布式锁。这样同一时间只有一个线程操作缓存,解决了并发问题。同时在后续读请求中时读到最新的缓存,解决了不一致的问题。
更新数据时同时更新缓存,但是给缓存一个较短的
TTL。
当然除了这个策略,在计算机体系还有其他几种经典的缓存策略,它们也有各自适用的使用场景。
Write Through
先查询写入数据key是否击中缓存,如果在 -> 更新缓存,同时缓存组件同步数据至DB;不存在,则触发 ·。
而一般 · 有两种方式:
Write Allocate :写时直接分配 Cache line
No-write allocate :写时不写入缓存,直接写入DB,return
在 Write Through 中,一般采取 No-write allocate 。因为其实无论哪种,最终数据都会持久化到DB中,省去一步缓存的写入,提升写性能。而缓存由 Read Through 写入缓存。
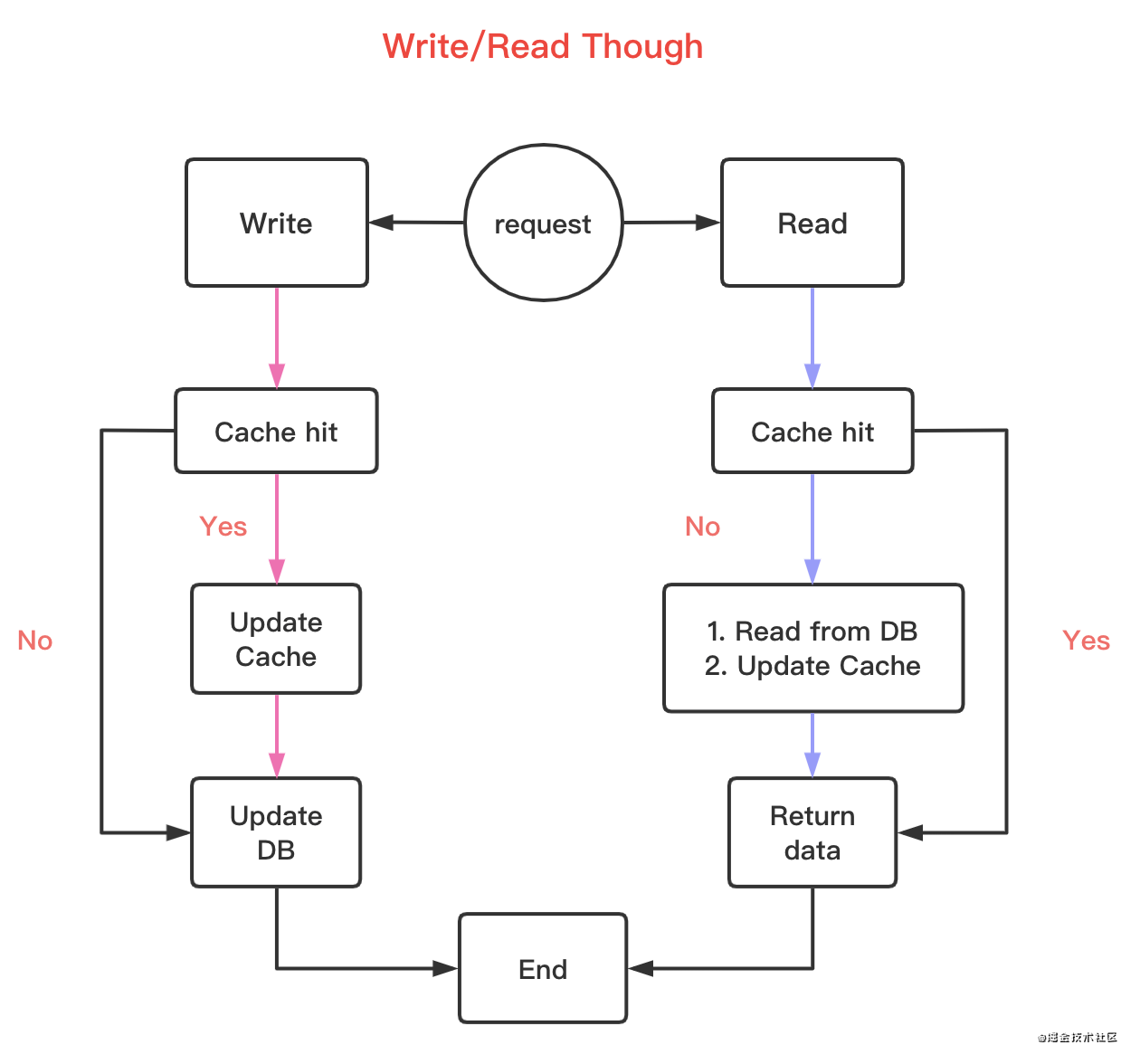
这个策略的核心原则:用户只与缓存打交道,由缓存组件和DB通信,写入或者读取数据。在一些本地进程缓存组件可以考虑这种策略。
Write Back
相信你也看出上述方案的缺陷:写数据时缓存和数据库同步,但是我们知道这两块存储介质的速度差几个数量级,对写入性能是有很大影响。那我们是否异步更新数据库?
Write back 就是在写数据时只更新该 Cache Line 对应的数据,并把该行标记为 Dirty。在读数据时或是在缓存满时换出「缓存替换策略」时,将 Dirty 写入存储。
需要注意的是:在 Write Miss 情况下,采取的是 Write Allocate ,即写入存储同时写入缓存,这样我们在之后的写请求只需要更新缓存。
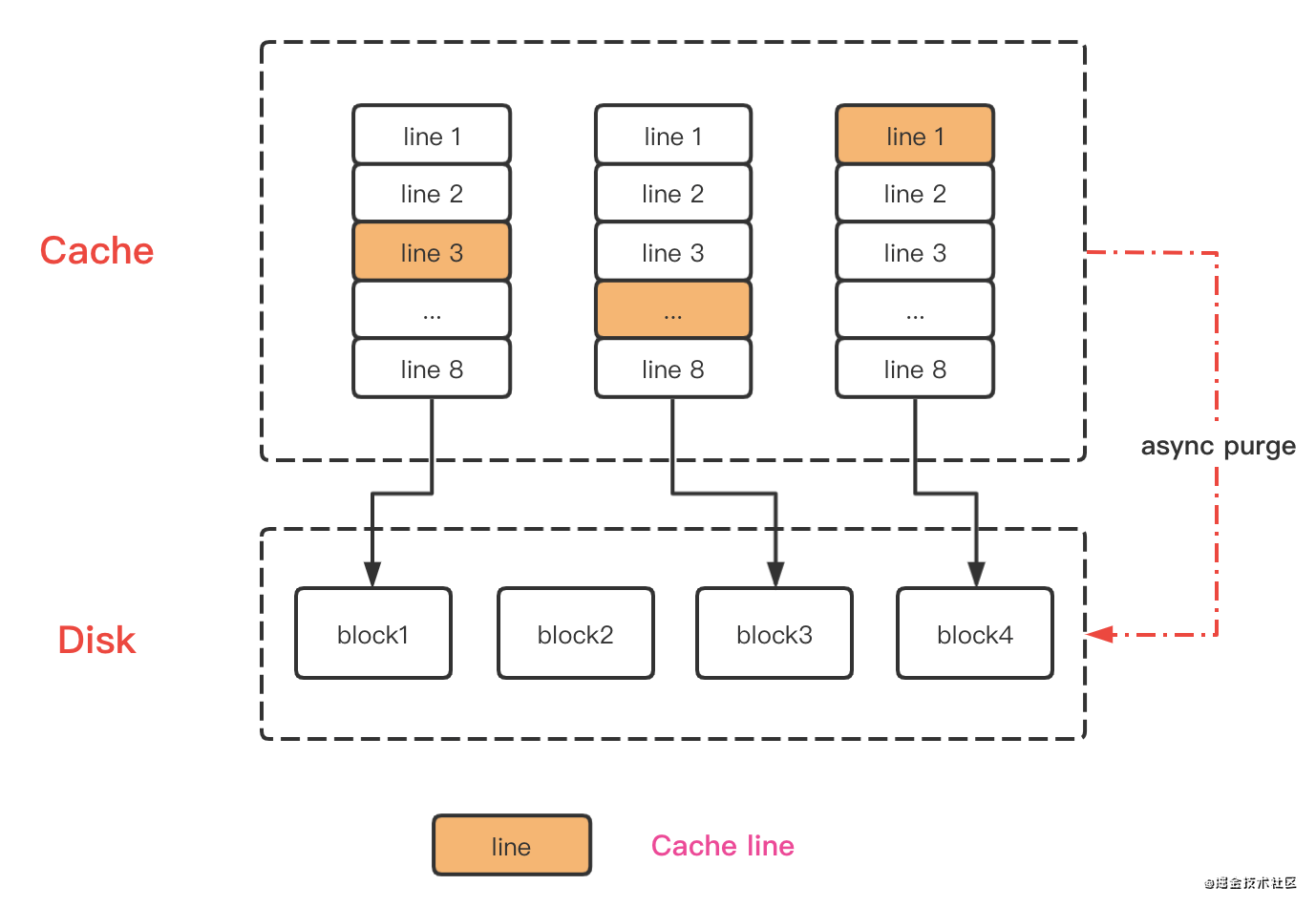
async purge此类概念其实存在计算机体系中。Mysql中刷脏页,本质都是尽可能防止随机写,统一写磁盘时机。
Redis
Redis 是一个独立的系统软件,和我们写的业务程序是两个软件。当我们部署了Redis 实例后,它只会被动地等待客户端发送请求,然后再进行处理。所以,如果应用程序想要使用 Redis 缓存,我们就要在程序中增加相应的缓存操作代码。所以我们也把 Redis 称为 旁路缓存,也就是说:读取缓存、读取数据库和更新缓存的操作都需要在应用程序中来完成。
而作为缓存的 Redis ,同样需要面临常见的问题:
缓存的容量终究有限
上游并发请求冲击
缓存与后端存储数据一致性
替换策略
一般来说,缓存对于选定的被淘汰数据,会根据其是干净数据还是脏数据,选择直接删除还是写回数据库。但是,在 Redis 中,被淘汰数据无论干净与否都会被删除,所以,这是我们在使用 Redis 缓存时要特别注意的:当数据修改成为脏数据时,需要在数据库中也把数据修改过来。
所以不管替换策略是什么,脏数据有可能在换入换出中丢失。那我们在产生脏数据就应该删除缓存,而不是更新缓存,一切数据应该以数据库为准。这也很好理解,缓存写入应该交给读请求来完成;写请求尽可能保证数据一致性。
至于替换策略有哪些,网上已经有很多文章归纳之间的优劣,这里就不再赘述。
缓存和存储更新顺序
这是开发中常见纠结问题:到底是先删除缓存还是先更新存储?
情况一:先删除缓存,再更新存储;
- A 删除缓存,更新存储时网络延迟
- B 读请求,发现缓存缺失,读存储 -> 此时读到旧数据
这样会产生两个问题:
- B 读取旧值
- B 同时读请求会把旧值写入缓存,导致后续读请求读到旧值
既然是缓存可能是旧值,那就不管删除。有一个并不优雅的解决方案:在写请求更新完存储值以后, sleep() 一小段时间,再进行一次缓存删除操作。
sleep 是为了确保读请求结束,写请求可以删除读请求造成的缓存脏数据,当然也要考虑到 redis 主从同步的耗时。不过还是要根据实际业务而定。
这个方案会在第一次删除缓存值后,延迟一段时间再次进行删除,被称为: 延迟双删 。
情况二:先更新数据库值,再删除缓存值:
- A 删除存储值,但是删除缓存网络延迟
- B 读请求时,缓存击中,就直接返回旧值
这种情况对业务的影响较小,而绝大多数缓存组件都是采取此种更新顺序,满足最终一致性要求。
情况三:新用户注册,直接写入数据库,同时缓存中肯定没有。如果程序此时读从库,由于主从延迟,导致读取不到用户数据。
这种情况就需要针对 Insert 这种操作:插入新数据入数据库同时写缓存。使得后续读请求可以直接读缓存,同时因为是刚插入的新数据,在一段时间修改的可能性不大。
以上方案在复杂的情况或多或少都有潜在问题,需要贴合业务做具体的修改。